
• El "Elemento Lineal Adaptable", también llamado Adaline (primeramente conocido como Neurona Lineal Adaptable), fue sugerido por Widrow y Hoff en su obra "Adaptive switching circuits", y una regla de aprendizaje la cual denominaron algoritmo LMS (least mean square).
• La red ADALINE es muy similar al Perceptrón, excepto que su función de transferencia es linear, en vez de escalón.
• Tanto el ADALINE como el Perceptrón sufren de la misma limitación: solo pueden resolver problemas linealmente separables.
Diferencias Entre La Regla Del Perceptrón Y El Algoritmo LMS
• El algoritmo LMS es más poderoso que la regla de aprendizaje del Perceptrón.
• La regla del Perceptrón garantiza la convergencia a una solución que categoriza correctamente el patrón de entrenamiento, pero la red resultante puede ser sensible al ruido ya que frecuentemente el modelo cae cerca de la frontera de decisión.
• El algoritmo LMS minimiza el error medio cuadrático, y por consiguiente trata de mover la frontera de decisión tan lejos como sea posible del modelo de entrenamiento.
• El algoritmo LMS ha encontrado muchos más usos que la regla de aprendizaje del Perceptrón. En esencia en el área del procesamiento digital de señales.
Diferencias entre:

Arquitectura de ADALINE

• La salida lineal obtenida del ALC se aplica a un Conmutador Bipolar.
• El Umbral de la F. de T. se representa a través de una conexión ficticia de peso Wo (b)
Red ADALINE

ADALINE de dos entradas

Mínimo Error Cuadrático

Ecuaciones Importantes en el Algoritmo LMS

Condiciones para la Estabilidad

MATLAB
Neural Network Toolbox
Inicializaciôn y Diseño
[W,b]=initlin(P,T)
Las redes lineales pueden ser diseñadas directamente si se conocen sus vectores de entrada y objetivo por medio de la función solvelin, la cual encuentra los valores de los pesos y el bias sin necesidad de entrenamiento.
[W,b]=solvelin(P,T);
W=solvelin(P,T);
Regla de Aprendizaje en ADALINE
- ADALINE utiliza un aprendizaje OFF LINE con supervisión.
- Este aprendizaje es la llamada Regla de Widrow-Hoff (Regla Delta o Regla del Mínimo Error Cuadrático Medio LMS Least Mean Square.
Regla de Widrow-Hoff
Consiste en hallar el vector de pesos W deseado, único, que deberá asociar cada vector de entrada con su correspondiente valor de salida correcto o deseado. La regla minimiza el error cuadrático medio definido como:

donde:  es la función de error
es la función de error
Esta función de error está definida en el espacio de pesos multidimensional para un conjunto de entradas, y la regla de Widrow-Hoff busca el punto de este espacio donde se encuentra el mínimo global.


Con función de activación lineal Con función de activación sigmoidal
Se utiliza el método de gradiente decreciente para saber en qué dirección se encuentra el mínimo global de dicha superficie. Las modificaciones que se realizan a los pesos son proporcionales al gradiente decreciente de la función de error, por lo que cada nuevo punto calculado está más próximo al punto mínimo.


La regla de Widrow-Hoff es implementada realizando cambios a los pesos en la dirección opuesta en la que el error está incrementando y absorbiendo la constante -2 en lr.
en forma de matriz: 
Transformando a la expresión del bias (considerando que el bias son pesos con entradas de 1):

Algoritmo de aprendizaje en ADALINE
1. Se aplica un vector o patrón de entrada PR en las entradas del ADALINE.
2. Se obtiene la salida lineal aR = WPR y se calcula la diferencia con respecto a la salida deseada: ER =TR-aR
3. Se actualizan los pesos: W( t+1 ) = W(t) + lrERPR
4. Se repiten los pasos 1 al 3 con todos los vectores de entrada.
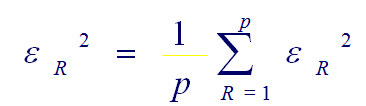
5. Si el error cuadrático medio es un valor reducido aceptable, termina el proceso de aprendizaje, sino, se repite otra vez desde el paso 1 con todos los patrones.
ENTRENAMIENTO ADALINE
El entrenamiento de la red consiste en la aplicación consecutiva de la regla de aprendizaje para un patrón completo de entrenamiento
El entrenamiento comprende la aplicación de la regla de Widrow-Hoff (determinación de las diferencias en los pesos), actualización de los pesos y determinación del error.
Este proceso se realiza por medio de la aplicación de la entrada a la red, para un patrón completo de entrenamiento, o un vector de entrada
Por medio de Matlab, se puede realizar el entrenamiento por medio de learnwh, realizando las funciones siguientes:
A = simulin (P,W,b)
E = T - A
[dW,db] = learnwh (P,E,lr)
W = W + dW
b = b + dW
En MATLAB:
E = T - A;
[ dW, db ] = learnwh( P, E, lr )
lr es la tasa de aprendizaje. Si es grande, el aprendizaje es rápido, pero si es demasiado grande, el aprendizaje es inestable y puede incrementarse el error.
lr = maxlinlr( P ); % si no se utiliza bias
lr = maxlinlr( P, ‘bias’ ); %si se utiliza bias
W = W + dW;
b = b + db;
Sin embargo, si se procede por medio de las funciones anteriores, es necesario realizar un número de repeticiones suficiente para hacer que el error calculado sea igual a cero a través de la aplicación de la regla W-H para un patrón completo de entrenamiento
En Matlab, se puede realizar el proceso de entrenamiento de una capa de red lineal adaline por medio de la función
trainwh():
Esta función aplica repetidamente entradas a la red lineal, calcula el error en base al vector objetivo, y asigna pesos y umbrales
La sintaxis de la función es:
tp = [disp_frec max_epoch err_goal lr ]
[W,b,ep,tr] = trainwh(W,b,P,T,tp)
tp es un parámetro que indica la frecuencia de progreso en el entrenamiento, el máximo de repeticiones, el error mínimo permisible y la tasa de aprendizaje (ver Aprendizaje) y puede contener valores nulos o NAN.
La función regresa los pesos W, los umbrales b, el número de repeticiones usado ep y un registro del error de entrenamiento tr .
EJERCICIO:

Iteraccion 1:


Iteración: 3







{kind=link}